
Asynchronous programming allows the development of services that can handle millions of requests without saturating memory and CPU utilization. Support for asynchrony is usually baked into the programming language; we take a look at async support in Rust, a type-safe and memory-safe systems programming language that guarantees safety at compile time using rules that eliminate many issues prevalent in traditional languages. We take a peek at the inner workings of Tokio, an asynchronous runtime for Rust that provides scheduling, networking, and many other primitive operations for managing asynchronous tasks. Runtime libraries rely on the operating system for registering and dispatching asynchronous events. We compare the different asynchronous APIs that Linux provides and conclude why the new io_uring interface is the best approach. This article was originally written in 2022-09.
Introduction
The need for asynchronous programming grew when traditional multithreaded programs failed to meet the demands of handling a huge number of requests without upgrading the hardware. Traditional threads provide their own call stack and are periodically placed on a core as part of a context switch by the operating system, to advance their execution. Because of these memory requirements, spawning a thread for handling every request becomes infeasible in terms of memory usage when the number of requests grows. Supporting asynchronous programming on a language level needs constructs built into the language as well as a runtime library for managing asynchronous green threads (tasks) and scheduling them on CPU cores. This runtime is also responsible for interfacing with the operating system and dispatching resources associated with each event that the OS emits.
Rust is a programming language that first had its 1.0 release back in 2014. This systems programming language promises safety and efficiency for programs that serve all kinds of functionality e.g. web servers, operating systems, GUI and CLI programs, machine learning models, game engines and etc. Rust enforces some rules at compile time that allow the programmer to write memory and type-safe code without the need for excessive testing. Even with testing, traditional programming languages like C/C++ still fail to create memory-safe programs, even if these programs were written by the best programmers in the world. Some examples of memory issues that lead to dangerous vulnerabilities in software include buffer and stack overflows, use-after-free, out-of-bounds indexing, double freeing and etc. Rust tries to solve all these problems at compile time while providing a modern and standard syntax for programmers.
Asynchronous support is built into the Rust language. Rust uses the concept of Futures (a value that might be available in the future) and state machines to create resumable green threads that use a cooperative strategy to run themselves to completion. There can be other futures inside a future leading to the creation of a tree-like structure where the futures at the root, called a task, are directly managed by the runtime, and as the runtime polls the task for advancement, the task then polls its inner futures to completion. There leaf futures of this tree are futures that communicate with the I/O driver and the operating system. They register resources with the OS and wait for the OS to emit events, stating the status of those resources.
Tokio is an asynchronous runtime for the Rust programming language. It provides a scheduler, an I/O and time driver, and other functionalities like networking, inter-task communications, and synchronization primitives. Tokio provides a multithreaded scheduler that creates multiple workers on different threads. These workers each have a run queue that tasks reside in; they then pop tasks from their run queue and try to advance them to completion. The I/O driver uses an abstraction over different operating systems for registering events. It then waits for events to come from the OS and iterates through all of them, dispatching tasks that were blocked on the resource associated with each event.
Linux provides different system calls for working with asynchronous operations, these system calls tell the called about the readiness of file descriptors it was given. The problem with these system calls is that they don’t work as expected for file operations and always return a read status for file descriptors backed by regular files. For this reason, io_uring was introduced back in 2019 in the Linux kernel. It provides a uniform asynchronous interface at programs can use to manage all their asynchronous operations.
The Rust Programming Language
Rust is a new programming language made to create safe and efficient systems by modern standards. The thing that makes rust safe is a set of rules that rust enforces on the programmer during the compilation time. These rules are designed to catch memory bugs and race conditions in multi-threaded programs. Rust does all these while still being as efficient as the C programming language. A huge portion of software vulnerabilities is because of memory safety violations, things such as buffer overflow, use after free, and index out-of-bounds. There have been many attempts at trying to reduce these memory violations by statically checking C/C++ code but were mostly in vain. Today more than 70% of software vulnerabilities are because of memory safety issues [2]. For this reason, companies like Google and Mozilla started to come up with languages such as Go and Rust respectively. These new languages aim to be as efficient as C/C++ but without all their memory issues. Rust is different from Go in terms of how they manage their memory; Go is garbage collected whereas Rust lacks one and most values are simply dropped at the end of the scope.
Rust has become the most loved language every year since 2016 in Stackoverflow surveys [16] and has seen a significant adaptation among companies and individual developers. For example, in the embedded area companies like STMicrocontrollers and Espressif Systems introduced their community projects for enabling the use of the Rust programming language on their SoCs and modules.
The Rust programming language was first conceived back in 2009 in Mozilla and had its 1.0 release in 2014. Rust achieves its safety using two new concepts: ownership and lifetimes which we will be talking about shortly. The main drawback of using Rust is its steep learning curve. Like languages such as Haskell or Prolog, Rust introduces new concepts and new semantics that have a striking difference from what most system programmers are accustomed to. When starting to learn Rust, most of the time will be spent clashing with the compiler and trying to get the code to run.
Overview
Rust inherits from both object-oriented and functional paradigms. It supports generics, enums, pattern matching, and modules and has support for polymorphism using traits; traits are like interfaces in Java and allow types that implement them to be used as an instance of that trait or perform constraints on other types. Variables are by default immutable and can only be mutated if explicitly marked with the mut keyword.
One of the most loved features of Rust is its easy-to-use build system and package manager called Cargo. Cargo can download packages, resolve dependencies, build projects for different targets and so much more. Rust has a packages registry with more than 50,000 packages (or crates as we call them in Rust).
Ownership
For Rust to not use a garbage collector it needs to know when it is ok to free values; it does this using the concept of ownership. Ownership has three rules which are enforced by the compiler:
- Values in Rust only have one owner.
- There can only be one owner at a time for a value.
- When the owner goes out of scope the value is dropped. In listing 1 we can see an example. At line \( 11 \) a new scope is started using a curly bracket; this scope ends at line \( 15 \) with a closing bracket. At line \( 12 \) a new variable called \(x\) is created and assigned a value of \( 22 \). After its scope is ended at line \( 15 \) the \( x \) is dropped. If we try to use the value of \( x \) at line \( 17 \) we hit a compile error.
| |
Listing 1: Ownership
At line \( 19 \) a heap-allocated array (a vector) is created and is assigned to an immutable variable called \( a \). The ownership of the vector is then passed from \( a \) to another variable called \( b \). After this assignment, we cannot use \( a \) anymore and the print statement at line \( 23 \) would fail at compile time.
\( b \) is then passed to a function that takes a vector as its single argument. In this case, the ownership of our vector is passed into the function and is given to the variable \( numbers \). At the end of the function, the vector is freed because its owner which is \( number \) goes out of scope. Thus, using \( b \) at line \( 27 \) is a compile error. [17](Chapter~4.1)
Borrowing
If you wanted to use a variable without taking its ownership, Rust provides a concept called Borrowing. Borrows are in a sense references or statically checked pointers that allow the use of a non-owned variable as long as only one of the following conditions hold:
- There is only one mutable reference to a variable
- There are any number of immutable references to a variable
In listing 2 a vector is created and is assigned to a variable called \( nums \). At lines \( 4 \) and \( 5 \) two immutable references are created. At line \( 6 \) pushing a new value into \( nums \) fails because using an associated function such as
pushtakes a mutable reference to that variable and thus this violates the borrowing conditions: There cannot be a mutable reference to a variable along with other immutable references. The statement in line \( 7 \) also fails for the same reason. At line \( 11 \) after the references are out of scope, we are allowed to take mutable references to variables.
| |
Listing 2: Borrowing
At line \( 13 \) a new mutable reference is created. Since there can only be one mutable reference to a variable at a time (same as above push takes a mutable reference from the associated variable). An important observation is that if we removed the statement at line \( 17 \) then the push operation at line \( 15 \) wouldn’t fail; this is because the rust compiler is smart enough to notice that the mutable reference \( num4 \) is not used anymore after the push operation and is immediately freed after the push.
These rules are enforced by the Rust compiler and prevent memory-safety issues described before such as freeing more than once, use after free, and data races. These rules, however, hinder programmers from easily creating data structures such as linked lists or interface with hardware and are forced to use unsafe blocks. In these blocks, Rust ownership and borrowing rules don’t apply.[17](Chapter~4.2)
Lifetimes
Rust avoids situations where a resource is used after it has been freed in other places using lifetimes. Lifetimes and lifetime annotations allow the compiler to understand the scope in which a variable is valid. The Rust compiler can infer the lifetime of variables in most cases and manual annotation is not needed. For example, the lifetime of \( nums2 \) and \( nums1 \) in listing 2 ends at line \( 10 \).
An example where manual lifetime annotations are needed is described in listing 3. In this example, the \( smaller \) function takes two references and returns a reference. Without lifetimes annotations we can’t make the compiler ensure that when the program runs it avoids cases where the reference that the function returns has been freed beforehand and thus is an invalid reference. Lifetime annotations are like types; sometimes you have to manually specify the type of a variable because the compiler cannot infer it. In our case, the lifetime annotations define the relationship between the inputs and the output that the programmer desires, and then the compiler can analyze it [17](Chapter~10.3).
The lifetime annotation \( `a \) tells the compiler that the return value should live as long as the smaller lifetime of the two input references.
| |
Listing 3: Lifetimes
Concurrency
Rust does not provide a runtime library to manage and schedule threads but instead uses a one-to-one mapping model where all its threads are mapped to OS threads. Rust supports synchronization primitives such as mutex, conditional variable, atomic operations, barriers and etc. Rust uses lifetimes to decide whether a resource should be unlocked; if a resource that is behind a lock goes out of scope the lock is unlocked. One can send ownership of variables between threads through message passing mechanisms such as channels. It should be noted that Rust cannot stop the programmer from creating deadlocks using primitive synchronizations for example [17](Chapter 16.1).
Conclusion
In this section, we introduced Rust, a relatively young systems programming language that provides comparable efficiency and safety guarantees missing from other languages such as C/C++. We outlined the reasons that lead to its creation at Mozilla and discussed the mechanisms and rules by which the Rust compiler can eliminate memory-safety and type-safety issues plaguing the traditional programming languages.
Asynchronous Programming
In this chapter, I am going to discuss multitasking with which operating systems are able to run multiple tasks at the same time. We explore preemptive and cooperative multitasking and take a peek at how Rust achieves asynchrony.
Multitasking
Outside of the embedded space and in mainstream servers or personal computers, being able to execute multiple tasks at the same time is a must. For example on a physical server or VM, multiple processes could be running at the same time: one for a mail server, the other for serving a webpage, another routing traffic through a virtual private network, etc.
In most cases, there are more tasks than there are CPU cores and thus for the operating system to be able to run all these tasks at the same time, it needs to schedule more than one task on a single core. In order to create a feeling that all these tasks are running at the same time, the OS periodically switches out running tasks for those that are waiting to have their time slice. This is concurrency, an illusion that tasks are running at the same time. Parallelism is when tasks are actually executing at the same time on different cores.
There are two main ways to achieve multitasking:
- The OS forcefully pauses the execution of a task and switches it with another waiting one.
- The tasks themselves give up control of the CPU (yield) so that other tasks can execute.
Preemptive Scheduling and Multithreading
In preemptive scheduling, the operating system can decide when to switch out a task based on a hardware interrupt. This interrupt could be the result of a hardware timer timeout or other sources of interrupts. In figure 1 we can see that while the CPU is executing task \( A \) a hardware interrupt occurs and the operating system takes control of the CPU to execute the respecting interrupt handler and switch out task \( A \) with task \( B \) [11].

Figure 1: Preemptive Multitasking
These tasks in most operating systems are called threads of execution and each have a separate call stack reserved by the operating system. For threads to be resumed later in time, the CPU needs to save the thread’s state when it was preempted. This requires saving all the CPU registers at the point of preemption and restoring them when the thread resumes. These threads are multiplexed by the operating system and threads ready to be executed are given CPU cycles. If a thread blocks for some operation or its time slice has ended, the OS changes that thread for another ready thread.
Using threads to read from sockets or write to files are fine for a lot of applications. They have the advantage that their execution is controlled by the operating system and CPU time is shared fairly between them. Also in environments where tasks could be spawned from untrusted applications, it is important for the OS to be able to halt their execution. Their problem is that each thread needs its own call stack and thus, the more threads are spawned the higher the memory usage gets. When switching between threads, there is an overhead in saving the registers and restoring them again for the thread to continue. This back and forth between the thread on the operating system level is costly when applications need high performance.
If you use blocking interfaces for doing I/O, e.g. wait until \( x \) amount of bytes is read from this socket, you would need a separate thread for each call; one thread to read from a socket, another to fetch some records from a database, and so on.
In this method, the application uses the OS APIs to create user threads that map to kernel threads. This way the application does not need to have the facilities for managing threads and the binary sizes are smaller.
Cooperative Scheduling and Asynchrony
In Cooperative scheduling, tasks themselves yield execution to allow other tasks to run on the CPU. This is different from preemptive scheduling where the OS had to pause the execution of a task by force [11]. Cooperation is usually done with the help of the language and compiler and a runtime library. This runtime could either be embedded into the language itself or in the case of Rust, be included as a dependency.
Cooperative scheduling is useful for situations where there is a lot of I/O happening and if threads were used for each blocking operation, most of the time of that thread would simply be spent waiting for that operation (waiting for bytes to arrive from a socket or reading a file from disk). In asynchronous operations, however, the calling thread does not wait for the operation to be available and simply goes to do other things. When the resource associated with the asynchronous operation is ready, it notifies the thread that it can start executing the codes after that asynchronous operation.
In this type of scheduling, tasks are more fine-grained than threads and multiple tasks can be assigned to run on a single thread. For example, we can create a task for listening on a socket \( TaskA \) and another one for saving some information into a database \( TaskB \). Both of these tasks can be run on the same thread. When \( TaskA \) tries to read from the socket and no data is available, it saves its state and yields. After that, since our thread is now not doing anything it can try to execute \( TaskB \); \( TaskB \) executes and tries to write as many bytes as possible and then saves its state yields to the runtime. Now our thread goes to sleep and waits for either of the tasks to be available for execution. If there are new bytes available at the socket, for example, the operating system notifies the runtime and the runtime in turn wakes up \( TaskA \) and executes it on our thread. In figure 2 we can see an example of this scenario.
Saving the state is usually done by the language. In Rust, all the state needed for a task, for example, local variables or some parts of the call stack, is stored in a struct. The code for creating this struct and inserting the values into them is automatically generated by the compiler. In this way, the tasks don’t need a separate call stack and use a shared one (that of the thread that they are running on). Now we can generate millions of tasks without having to worry about memory limitations.
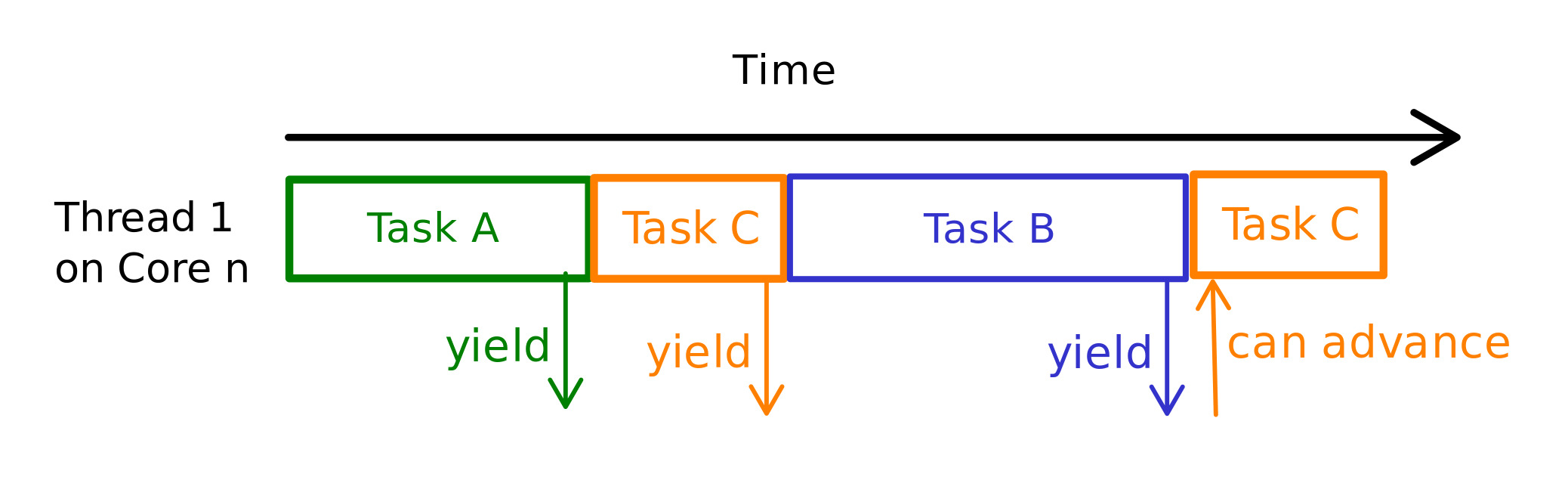
Figure 2: Cooperative Multitasking
This method uses a kind of many-to-one mapping where multiple user tasks are mapped onto a user thread which themselves are mapped to a kernel thread. Its disadvantage is that a rouge task that does not yield, can starve all the other tasks waiting to be executed. Because of this, cooperative scheduling is usually used in environments where tasks can be trusted e.g. inside a project where tasks are created by the developers themselves.
Comparison
Let’s check out an example that outlines the difference between multithreading and asynchrony.
In listing listing 4 we can see a simple TCP server that listens on a port for new connections. Each time a connection arrives from a client, it creates a new socket for the client and passes that connection to a new thread. The handle_connection function is used to manage a single connection on a separate thread.
Depending on the memory of the machine that this server is run on, this approach is probably fine for thousands of connections; but when the number of connections gets to millions the memory requirements of the server process become infeasible.
| |
Listing 4: Threaded TCP
We can use asynchronous tasks in Rust to handle connections concurrently. In this way, a single thread can handle multiple tasks and the maximum number of connections can go up to millions (of course if we ignore other limitations). The code in listing 5 shows an example of using asynchronous tasks in Rust using the Tokio runtime. As you can see, asynchronous code looks a lot like normal synchronous code.
| |
Listing 5: Async TCP
Futures and State Machines
Rust has support for cooperative tasks using futures and async/await. A future is a value that will be available at some time later. Instead of blocking for the value to be available, the caller can advance to do other things and only come back when the future is resolved and the value is ready. The cooperative tasks in Rust are a kind of future and futures are structs that implement a trait (interface) called \( Future \) (listing 6). Types that implement the \( Future \) trait must implement a method called \( poll \) and specify the value that the future will resolve to. For example, you can call a future that returns the number of open file descriptors of the current process; when this future resolves it returns an integer.
| |
Listing 6: Future Trait
The \( poll \) method’s output type is an enum called \( Poll \) that has two items. Calling the \( poll \) method tries to run the future to completion; if the future completes it returns Ready(T) with the value inside it and if the value is still not ready it returns Pending.
Asynchronous functions in Rust return a structure that implements the \( Future \) trait and its \( poll \) method. If this future resolves, the type of the value in Ready(T) is the same as the return type of the \( async \) function. This is done by the compiler and allows the programmer to write asynchronous code that looks similar to normal synchronous code. We can use the \( await \) keyword inside an \( async \) function to wait for the value of another future.
The Rust compiler converts \( async \) functions into a state machine (a struct) that implements the \( Future \) trait. This state machine is the future that is returned when an \( async \) function is called. Listing 7 shows an example of such function. At line \( 4 \) we await reading all the contents of a file into a byte array; when reaching this statement while executing the task, since reading from disk is much slower than the speed of our processor, the task returns immediately return Poll::Pending to allow other tasks to proceed. read_all_file is another \( async \) function and calling it returns a future; \( await \)ing on that future stops the outer future (our \( async \) function) from going further and causes the outer function to return [13] [15] [14].
After the file has been read into the file_bytes buffer, the pipe_to_socket future is polled again it resumes from where it left off, after \( 6 \) and goes to \( await \) another future which tries to create a UDP socket. This goes on until the whole function is executed; each time the function hits an \( await \) point, it \( yields \) to the runtime so that other tasks can advance. The state of the function is saved across \( await \) points. For example, when waiting to receive bytes from the socket, the file_bytes and the socket variables are saved inside the compiler-generated struct and are used after the future (our function) is polled again to resume.
| |
Listing 7: Async Function Example
This yielding and resuming later creates a state machine. The state machine for the \( async \) function in listing 7 is shown in figure 3.
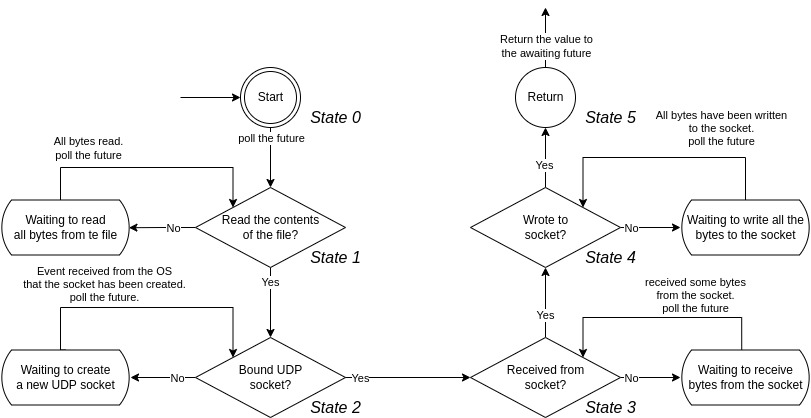
Figure 3: Future State Machine
As you can see, each time an \( await \) point is hit while executing a future, the control is yielded back to the runtime to execute other tasks. After an event occurs that the future is waiting on, the runtime finds the future waiting on that event and tries to poll it again so the future can progress. Each time a future returns to waiting on a resource, the runtime registers that resource to for example an operating system. The runtime then listens for events. These events come from the operating system signaling the runtime that some resource that has been registered with it, is now ready [14].
An example of what the compiler-generated state machine could look like is outlined in listing 8 (note that the code might not be semantically correct but nevertheless, it serves as a good example of how futures behave internally). The type of our state machine could be a simple enum with 6 different enumerations. Each enumeration is a state that contains all the necessary data needed to pause and resume the state machine. We implement the \( Future \) trait for this type and add a poll method for it. Each time the poll method is called, it tries to advance the state machine. It first determines which state it is in using pattern matching and then runs the code generated for that state.
For example, if the state machine was on State1 and it was polled by the runtime, first it would extract the variables stored in the current state, in the case of State1 the only variable is a future. This future is the result of calling the \( async \) function read_all_file when transitioning from State0 to State1. It would then try to poll the read_all_file future, if the future was not ready and returned \( Pending \) then the result of our outer future would be \( Pending \). However, if polling read_all_file reloved to a Poll:Ready(file_bytes) then we can transition to the next state State2 by first creating an instance of State2 and passing in the required variables, naming our byte array and the result of calling UdpSocket::bind which is a future. These variables are part of the state that our stat machine carries.
| |
Listing 7: Generated State Machine
This state machine generation is done by generators. A generator is a “resumable function” that syntactically resembles a closure but compiles to much different semantics in the compiler itself [18]. The Rust compiler inserts \( yield \) operation in place of \( await \)s so that when the result of an \( await \) is Pending then the future pauses and yields; so each yield is in fact a state of our state machine. The Pin type in listing 6 makes sure that the wrapping type does not move around in memory; this is important in the case of self-referential structs where if the object is moved, its internal pointers to itself will be invalidated. The state machine that the compiler generates has these self-referential pointers and thus these futures must be pinned [14].
Executors
When a future is polled and it returns Pending something has to poll them again when they are able to make progress, otherwise our state machine won’t advance. In the previous sections, we said that the “runtime” does the polling and that’s true; the part of the runtime that polls futures to completion is called the executor. Listing 9 shows a very basic and primitive executor. It has a queue where futures are pushed into as tasks and it repeatedly tries to pop a task from the start of the queue and run it. Tasks are the futures that the executor works with; an example of a task is outlined in listing 10. Tasks are structs that usually hold an instance of a future in them, when we say “run a task” we mean to poll the future inside that task [15].
| |
Listing 9: Executor
| |
Listing 10: Task
In listing 9 when a task is popped and its future is polled, two things can happen, either the task’s future returns Poll::Ready(value) in which case there is nothing else to do, since the task has finished to completion, or it returns Poll:Pending indicating that this task has to be polled on a later time (for example it might be waiting on a socket or a read from the disk). For a task to be able to be run again, it needs to be added into the run queue of the executor; the question that remains is who does that?
Wakers
Wakers are the mechanism that Rust uses to signal the executor that a given task should be run (its inner future be polled). Wakers have a wake() method that when called, does this signaling. In the context of futures, wakers are usually wrapped in a Context type and are passed to the poll method of that future; listing 11 shows an example of a Context struct. For our basic executor calling wake() on the waker of the context of a task, would simply add that task back to the executor run queue so that it can be polled once again. If the executor was asleep, it would also wake up the executor [15].
| |
Listing 11: Context
Future Tree
The futures that we have seen so far all call other futures. In line 4 of listing 7 for example, the async pipe_to_socket function waits for the output of the future that calling read_all_file results; an example of what this function could look like is shown in listing 12. The same thing happens throughout the function. The futures that we are awaiting on themselves can await on other futures. This structure forms a tree [3] [12].
| |
Listing 12: Nested Async Function Example
Figure 4 shows this tree for the example in listing 12 and 7.
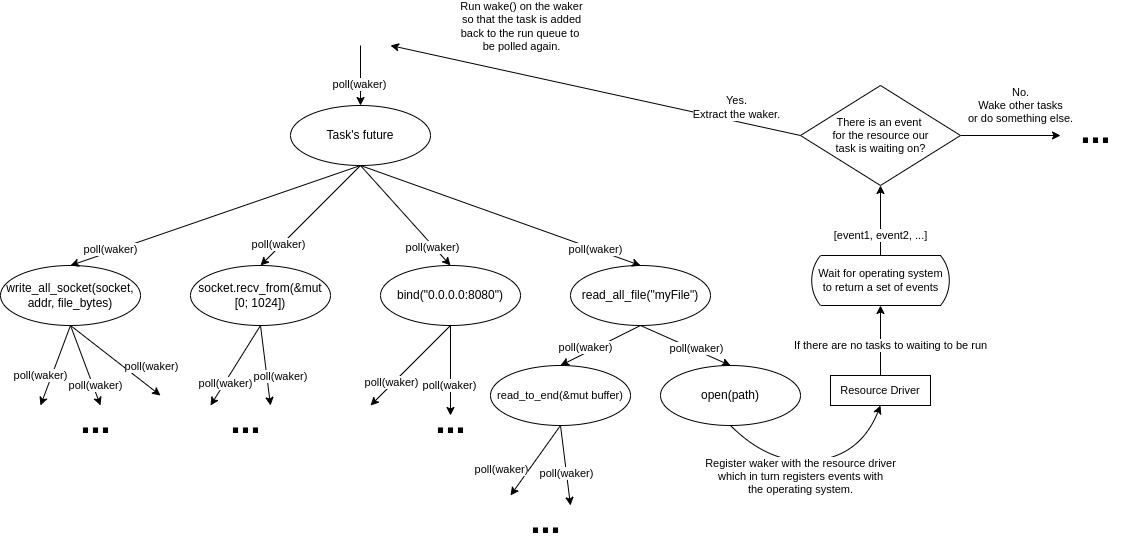
Figure 4: Future Tree
As we can see tasks are the root of our future tree and are the futures that our executor is in contact with. Executors provide APIs for spawning new tasks by giving them a future. In listing 13 we call our async pipe_to_socket function which returns a future, and pass this future to the spawn method of our executor (in this case Tokio’s executor). The spawn method creates a task out of this future and adds it to the run queue of our executor.
| |
Listing 13: Root Future
As we saw in line 28 of our state machine in listing 8 when we call poll on our main task’s future, it in turn, tries to poll its inner futures. But we can’t keep polling other futures, somewhere in this tree there are futures that when they are polled, other than returning Poll:Pending they also make sure that the task that polled them will be run again when the resource its waiting on is available. These are the futures at the leaf nodes of our future tree. In figure 4 when we poll our task for the first time and give it a waker, which when its wake() method is called adds this task back to the run queue, it tries to poll the read_all_file future. The read_all_file future in turn tries to poll the open(path) future. The open(path) future is a leaf future so when it is polled, instead of polling another future it registers its waker and the resource it’s waiting on with the driver (also called the reactor). In this case, the future asks the driver to open a file with the given path and the driver in turn asks the operating system to open the given file. The waker registered with the driver is passed down from the main task and the driver keeps a record of which wakers are related to which waiting resources. The leaf future then returns Poll:Pending and this return value is propagated back to the task and back to the executor. The executor then tries polling other tasks.
The driver periodically waits for the operating system to return a set of events. It then iterates through the events and dispatches all the wakers that have been registered with the given event’s resource. In our case, when the file has been opened by the operating system, it returns an event. After seeing this event, the driver calls the wake() method on the waker registered with this event, and the task related to this waker is pushed back into the run queue to be polled again. When the task is polled again, since all of our futures are state machines and the future tree is somewhat a state machine tree, it starts polling from the root future all the way back down to the leaf future. The futures saved their state from the last time they were polled and now they resume from where they left off. This time when the leaf future is polled, it receives the resource it was waiting on (in our example, the file descriptor of the opened file) and returns Poll::Ready(fd) to its parent future. The parent future then goes on to poll the next future and so on.
Conclusion
In this section, we discussed different ways that multitasking could be done. We outlined the advantages and disadvantages of preemptive and cooperative scheduling and talked about how asynchrony helps us utilize our memory and CPU cycles. We saw how rust implements asynchronous programming through the use of aync/await keywords and futures. Finally, we saw an example of how the Rust compiler helps us to create state machines from these futures and how executors and runtime libraries run these futures.
Tokio
Tokio is an asynchronous runtime for Rust, it provides the executor we talked about in the previous section that allows running futures. It is by far the most widely used runtime in the Rust ecosystem and many other projects are built on top of Tokio. Tokio provides a whole host of functionalities:
- Task scheduler
- An I/O driver (reactor) for interfacing with the operating system
- Asynchronous network interfaces such as sockets
- Communication and synchronization primitives for working with asynchronous tasks such as different kinds of channels, mutex, barrier, condvar, and …
Tokio is broken into modules each providing different functionalities. Here we will be taking a closer look at the runtime module. This module does not expose a lot of APIs to the user of the library; most of them are for creating a runtime or spawning tasks unto the runtime. The runtime module is where the magic that allows writing high-performance asynchronous code in Rust happens and it itself consists of multiple parts [19].
- A scheduler for assigning tasks to be run on the available cores
- The I/O driver that wakes up waiting tasks when new events come form the operating system,
- A time driver with a resolution of one millisecond used for time-based scheduling
In the remainder of this chapter, we will be taking a closer look at the inner workings of the scheduler and the I/O driver of the Tokio runtime.
Scheduler
The scheduler has the job of assigning tasks to the CPU cores until they yield back to the scheduler. The future inside the task is polled and it runs on the CPU until it hits an inner future that needs an external resource to be resolved. Tokio provides two kinds of schedulers: Multithreaded and Single-threaded. Here we will be taking a look at the multithreaded scheduler (the inner workings of the single-threaded one is similar).
Multithreaded scheduler
When using the multithreaded scheduler (the default) Tokio creates a number of threads to scheduler tasks on. It then assigns a local run queue to each thread; threads then enter a loop where they constantly pop tasks from the start of their queue and run the task until it yields and then pops another one. When tasks are scheduled unto the runtime they usually come in batches by the I/O driver (when new events from the OS are received and corresponding tasks are woken to be added to a run queue) all these tasks get scheduled unto the local queue of one of the threads. Without any mechanism to distribute this load across all the available threads, we may experience resource underutilization where some threads are idle and others are doing much of the work.
To solve this issue and distribute the work uniformly, the Tokio scheduler uses work-stealing. When a thread has nothing else to do (its local run queue is empty), before going to sleep it checks the run queue of other threads for work and tries to steal some of their tasks. This is outlined in figure 5. Thread 2 has run out of tasks and before going to sleep it checks other threads for work; it iterates through all the threads in descending order and finds right away that thread 4 has work to steal so it steals half of the tasks of thread 4 from the beginning of the queue.
The good thing about this approach is that synchronization and cross-thread communication is mostly avoided as the load on the system increases and threads never reach an empty queue to try to steal from others. What happens when a thread tries to steal from other threads, doesn’t find any work to steal, goes to sleep, and then a batch of tasks is pushed unto the run queue of other threads? A mechanism must be implemented so that threads with work can notify other sleeping threads so that they can wake up and steal work [5].
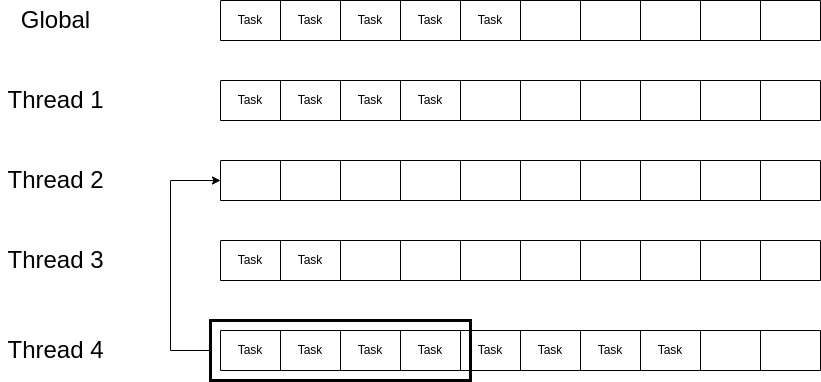
Figure 5: Stealing Work
Queue and Work Stealing Implementation
The run queue is backed by a circular buffer outlined in listing 14. The \( Arc \) type provides shared ownership of a value and is a thread-safe reference-counting pointer. Meaning that it’s a reference to an object in the heap and can be cloned as many times; once the last reference has gone out of scope the object itself is deleted from the heap. The circular buffer has a tail that is only updated by a single thread and read by multiple threads and a head that can be updated concurrently by multiple threads. It is backed by a constant-sized array of Tasks; the elements of this array are uninitialized at first. The Box type indicates that the value will be allocated in the heap.
Two handles are created from the local queue of each thread, one is a \( Steal \) handle and the other is a \( Local \). The local handle is used by a single thread to push and pop tasks from the queue and the steal handle is available for all other threads so that they can peek into this thread’s local queue and steal tasks if necessary. This is why the head and tail values are atomic; because they may be written to or read by multiple threads.
| |
Listing 14: Circular Buffer
The 32-bit unsigned head of the queue is actually made up of two 16-bit unsigned integers. The left-most 16 bits are called the steal head and the right-most 16 bits are called the real head. These two heads are used for stealing operations and act as a signal to other threads that specify whether someone is currently stealing from the given queue or not. The real head specifies the position of the next task to be popped and the steal head specifies the starting position of the tasks that are going to be stolen from a run queue.
Pushing tasks into the queue is done by first adding the task to the backing array at the position indicated by the tail and then incrementing the tail. Before pushing a task, the value of the real head is subtracted from the tail and is compared with the maximum length of the backing array; if there were enough space available, the pushing continues.
| |
Listing 15: Stealing
Popping is also straightforward, first, it is checked that the value of the real head and tail are not equal, if they are then the buffer is empty and no tasks can be popped. Otherwise, the tasks at position real_head are taken out from the buffer and the value of real head is incremented by one.
A simplified version of the stealing algorithm is outlined in listing 15. The steal_into function is called by the stealing thread on the steal handle of the run queue of the thread that it wants to steal from. This function takes a local run queue handle as the destination queue into which tasks will be stolen. Stealing threads pass their own run queue to this function.
Lines \( 3 \) through \( 9 \) load the tail and head values for the source and destination queues. The head value is unpacked into steal and real head. Unpacking is simply splitting the 32-bit value into two 16-bit values. At line \( 13 \), if the steal head and the real head of the source queue do not match then this means that another thread is concurrently stealing from this queue and the function returns immediately. At line \( 16 \) the number of tasks to be stolen \( n \) is assigned half of the number of available tasks on the source queue. To signal other threads that a stealing operation is underway, the real head of the source queue is advanced by \( n \) at line \( 22 \) and after repacking the head values into a 32-bit number, it is placed back into the atomic head field of the source queue. We then go through all the claimed tasks and transfer them one by one from the source queue to the destination queue. We then update the steal head of the source queue to match its real head; this signals that the stealing operation has ended. Finally, the tail of the destination queue is updated so that the stolen tasks can be popped and executed by the consumer thread. This procedure is depicted in figure 6.
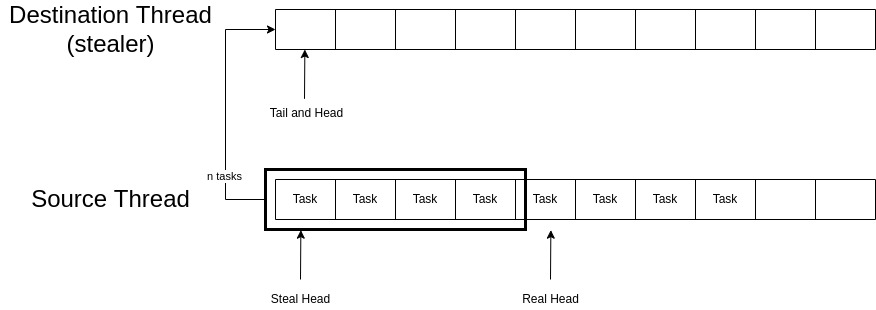
Figure 6: Stealing Tasks
For the sake of simplicity, all the code concerning memory orderings has been removed from the examples. There are also some subtleties that must be noted while pushing a task unto the run queue of a thread:
- If the queue is not full, then the task is simply pushed back to the queue.
- If the queue is full and there is a thread currently stealing from the queue (the steal head and the real head are not equal) then this means that the run queue will be empty soon so the given task is instead pushed to the global queue. The global queue (also called the inject queue) is a shared linked list among all the threads where the insertion or deletion of tasks in the queue is guarded by a mutex.
- If the queue is full and no other thread is currently stealing from the local run queue, then
push_overflowis called. This function takes half of the tasks of the local run queue and adds them in a batch into the global queue.
Workers
There are a couple of important data structures that are outlined in listing 16. When the multithreaded scheduler is created, a number of workers are also created. Each worker is assigned to a newly spawned thread (one thread per worker). An instance of the \( Core \) structure is given to each thread; this struct contains data such as the local run queue, the number of ticks, etc. The \( Shared \) struct contains data that is shared across all workers (threads) such as the global queue (inject queue), a list of \( Steal \) handles corresponding to the queues of all the threads (for example \( remotes[2] \) corresponds to the \( Steal \) handle of the third worker’s run queue) and some other structures.
| |
Listing 16: Structs
The LIFO slot in the core structure is an optimization for message passing scenarios. When two tasks are communicating over a channel, the following scenario happens frequently:
- \( Task1 \) and \( Task2 \) are communicating over a channel.
- \( Task2 \) is currently blocked on side of the channel waiting for a message from \( Task1 \)
- \( Task1 \) sends a message through the channel
- \( Task2 \) is wakened up and is placed at the end of the run queue The problem here is that since \( Task2 \) is placed at the end of the run queue, there might be a lot of latency between the sending of the message by \( Task1 \) and its receive by \( Task2 \). For this reason, the Tokio scheduler has a LIFO (last in first out) slot where new tasks are placed inside it and when the scheduler wants to pop tasks from the queue, it first checks the LIFO slot for a task and only if it was empty goes for the other task at the head of the queue.
Let’s now take a look at how workers are created and what they do when they start. Listing 17 shows this procedure. First of all, each worker is run on a separate new thread. The workers then start executing statements inside a loop until the runtime is shut down. The \( tick \) field of the \( Core \) structure holds the number of iterations that the worker has had inside this loop. At line \( 15 \) the tick is incremented. If the value of tick is multiple of event_interval (part of the shared scheduler configuration) then the worker proceeds to try and run the driver at line \( 19 \). We’ll talk about the driver in the next section.
In line \( 23 \) the worker tries to acquire a task. The next_task function first checks the LIFO slot for a task and if it was empty it pops a task from the local run queue of the worker. Running a task as we discussed in the previous chapter, means pulling its associated future.
The steal_work function at line \( 30 \) would first try to steal from sibling workers into its run queue and return one of the stolen tasks (the stealing mechanism was explained previously) if no tasks could be stolen from the siblings, it then checks the global run queue for a task. If no tasks were available, the worker is parked (goes to sleep) until an influx of tasks prompts other threads to wake this worker up. Before going to sleep, some threads may also try to take and run the driver/
| |
Listing 17: Worker
I/O Driver
The runtime driver is protected by a mutex and only a single worker at a time can have control of the driver. Threads try to take control of the driver on a regular basis (every 64 ticks for example). The runtime driver is composed of different drivers that serve different purposes: I/O driver, time driver, process driver, etc. The I/O driver is responsible for listening to for events from the operating system and dispatching resources associated with those events.
In listing 17 at line 20, when a worker tries to run the runtime driver, it first has to lock a mutex, if the lock was successful (no other worker is in control of the driver) the worker can proceed. Here we will be focusing on the I/O driver of the runtime driver. (when the run_driver function is called it runs its inner drivers including the I/O driver).
The I/O driver contains a data structure that can save the records that specify which resources are associated with which events. Right now Tokio uses Mio a low-level I/O library for Rust; Mio is an abstraction over different operating systems’ asynchronous APIs [10].
The leaf futures register resources they are interested in with Mio through the data structure that the I/O driver provides. Mio then interfaces with the operating system and passes down these events using whatever API the underlying OS provides. The I/O driver then blocks on a call to poll function from Mio and waits for events to arrive. After receiving the events from the operating system, Mio passes up these events to the caller of poll, and its the caller’s job to handle which resources should be notified.
For example in the case of reading from a socket, when a task blocks for a socket to be readable, it is the I/O driver’s job to get the events from Mio, see that there is an event associated with the socket saying that the socket is now readable, and call the waiting task’s waker wake() method.
Listing 18 shows the function that gets called when running the I/O driver. At line \( 5 \) prepare an array of events (this array is reused across calls to the I/O driver). Then at line \( 9 \) the thread that is running the driver blocks on a call to poll passing the array of events to be filled and waiting for events to arrive from Mio (and hence the operating system). Once the events arrive, it iterates through them one by one and dispatches the sources associated with them (for example rescheduling tasks back on the run queue).
One important thing to notice is that the tasks are all scheduled on the run queue of the worker taking control of the driver, this is why earlier we said that tasks come in batches. Now we let the work-stealing algorithm do the rest and distribute the tasks across workers.
| |
Listing 18: Driver
Conclusion
In this section, we introduced Tokio: an asynchronous runtime for Rust. Tokio plays the role of the executor that we talked about in chapter Asynchronous Programming. We took a look at how the multithreaded scheduler works and what the work-stealing algorithm does and why it is important. We then dug deeper into the implementation of the queue used by the scheduler and how work-stealing functions with them. The inner workings of the workers were discussed, how they are created and run on their own thread, what data types they use and how they function. Finally, we took a more in-depth look at the I/O driver that has been discussed since chapter Asynchronous Programming.
io_uring
Linux provides a set of system calls for doing asynchronous I/O. epoll is an example of such a system call that is used in Mio as its Linux backend (see chapter Tokio section I/O Driver, These system calls can monitor a set of file descriptors such as network sockets and check their status for doing I/O, e.g. see whether the socket is readable.
epoll takes a set of interests containing the file descriptors that a process wants to monitor. It then returns a ready list (a subset of interest list) which is a set of file descriptors that are ready for I/O; the process can block on the epoll_wait system call until a set of ready file descriptors is returned by the kernel.
epoll for Files
Being able to use asynchronous I/O for file system operations is consequential for performance. Large-scale Webservers, SFTP servers, databases, and a lot of other applications all need the asynchrony that epoll provides; because when you reach a point where there are thousands of requests and concurrent connections, blocking for read and write operations on the file system can have a huge impact on performance.
The problem with epoll is that it always returns a ready status for files. In fact, using epoll is only sensible for file descriptors that normally block when being used for I/O such as network sockets and pipes. Because of this, Tokio and other libraries in different languages use a thread pool for file operations meaning when a future wants to do I/O on files, the request for I/O is sent to another thread and is executed synchronously there. This is where io_uring comes in. [9]
The I/O Uring
io_uring was introduced in Linux Kernel version 5.1 in 2019. The goal of io_uring is to replace old interfaces for async I/O and bring improved performance by reducing overhead for applications. io_uring solves the problem with regular files and brings a uniform API under which programs can enjoy the benefits of asynchrony.
io_uring uses two ring buffers. One for submitting requests to the kernel and the other for receiving the completion of those requests.
The io_uring_setup() system call is used by the program to create these two ring buffers. These two buffers are created using mmap with the goal of sharing them between user space and kernel space. This reduces the overhead of copying data structures between the two. [6]
Submissions are added to the submission buffer in the form of a submission queue entry (SQE) type. SQE is a struct with fields that can support a lot of the operations that a program would need, e.g. reading from a socket, creating a file, writing to a file, etc. After adding SQEs to the submission buffer, the program can call the io_uring_enter() system call to signal the kernel that there are SQEs available and that it should start reading them. A simplified version of the SQE struct is available in listing 19.
Different fields of this struct serve different purposes depending on the type of the operation. For example, if you wanted to do a rename operation as the opcode you would use IOURING_OP_RENAMEAT (one of the cases in a huge enum called io_uring_op), set addr as the old path and addr2 as the new path; other fields may also need to be filled. This is effectively equivalent to the renameat2 system call. [7]
| |
Listing 19: SQE
After processing the SQEs, the kernel submits completion queue entries (CQE) to the completion queue. Each CQE in the completion queue has had a corresponding SQE in the submission queue entry. The program then reads these CQEs and takes proper action based on their status. The user space can block and wait for CQEs using the same system call for submitting SQEs io_uring_enter().
Figure 7 shows a simple view of how these buffers work.
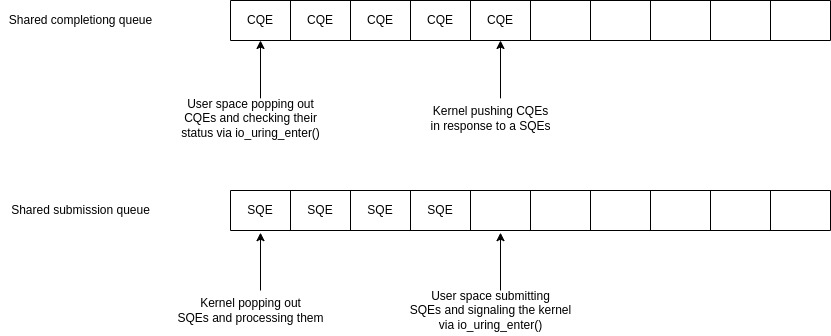
Figure 7: I/O urings
This work can be submitted and read in batches and thus, the number of system calls reduces significantly which can improve the performance of the application. One of the reasons that system calls can tax the performance so much is because of the security precautions that are taken by the operating system to avoid vulnerabilities like Specter and Meltdown [4] [8].
Conclusion
We talked about the asynchronous APIs that the Linux kernel provides for applications and took a peek into the inner workings of epoll. We then discussed how epoll falls short when it comes to asynchronous file operations and how runtimes using epoll have to resort to a thread pool for their file I/O. After that, io_uring was introduced as a solution to the shortcomings of previous async I/O APIs of Linux and we developed a view of how io_uring works. Tokio has been working on tokio_uring to experiment with the integration of tokio and io_uring [1].
Conclusion
In this post, the Rust programming language was introduced; we saw how concepts like ownership and borrowing work together to achieve memory and type safety at compile time. Traditional languages like C/C++ were notorious for easily allowing developers to make mistakes while managing their memory, causing dangerous security flaws and vulnerabilities to be rampant in programs written in those languages.
We then shifted our attention to asynchronous programming and talked about different multitasking methods such as preemptive and cooperative. We outlined the advantages and disadvantages of each method and concluded that to avoid saturating memory when the number of requests increases dramatically, we can use asynchronous tasks (green threads) instead of traditional threads that each had their own call stack. We then took a peek at how Rust allows writing asynchronous programs just as easy as their normal synchronous counterparts. Futures and the state machine that the compiler generates were discussed and saw how we need executors to poll these futures and need wakers to be able to reschedule future on to the runtime.
Next, we talked about Tokio, an asynchronous runtime for Rust, and outlined the different parts of it. We took an in-depth look at how tokio schedules tasks and how workers that run on a thread, manage their run queues. The I/O driver and its job with registering resources was also discussed. In the final chapters, asynchronous interfaces for the Linux operating systems were introduced and their advantages and disadvantages were outlined. We talked about how io_uring was introduced to resolve the shortcomings of the previous async interfaces.
References
You can cite this work through this DOI.
- [1] A crate that provides io-uring for Tokio by exposing a new Runtime that is compatible with Tokio but also can drive io-uring-backed resources. 2022. url: https://github.com/tokio-rs/tokio-uring.
- [2] Alex Gaynor. What science can tell us about C and C++’s security. 2021. url: https://alexgaynor.net/2020/may/27/science-on-memory-unsafety-andsecurity/.
- [3] Crate futures 0.1.30, Trait futures::future::Future. 2018. url: https://docs.rs/futures/0.1.30/futures/future/trait.Future.html.
- [4] Paul Kocher et al. “Spectre Attacks: Exploiting Speculative Execution”. In: 40th IEEE Symposium on Security and Privacy (S&P’19). 2019.
- [5] Carl Lerche. Making the Tokio scheduler 10x faster. 2019. url: https://tokio.rs/blog/2019-10-scheduler.
- [6] liburing manual: io uring.7. 2022. url: https://git.kernel.dk/cgit/liburing/tree/man/io_uring.7.
- [7] liburing manual: io uring enter.2. 2022. url: https://git.kernel.dk/cgit/liburing/tree/man/io_uring_enter.2.
- [8] Moritz Lipp et al. “Meltdown: Reading Kernel Memory from User Space”. In: 27th USENIX Security Symposium (USENIX Security 18). 2018.
- [9] Lord of the io uring: Asynchronous Programming Under Linux. 2022. url: https://unixism.net/loti/async_intro.html.
- [10] Mio: Metal IO library for Rust. 2022. url: https://github.com/tokio-rs/mio.
- [11] Philipp Oppermann. Writing an OS in Rust: Async/Await Chapter. 2020. url: https://os.phil-opp.com/async-await/.
- [12] Rust Documentation, Trait std::future::Future. 2022. url: https://doc.rust-lang.org/std/future/trait.Future.html.
- [13] Rust RFC 2033 experimental coroutines. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2033-experimental-coroutines.md.
- [14] Rust RFC 2394 async/await. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2394-async_await.md.
- [15] Rust RFC 2592 Future API. 2018. url: https://github.com/rust-lang/rfcs/blob/master/text/2592-futures.md.
- [16] Stack Overflow. Stack Overflow Developer Survey 2021. 2021. url: https://insights.stackoverflow.com/survey/2021#section-most-loved-dreadedand-wanted-programming-scripting-and-markup-languages.
- [17] The Rust Book. 2022. url: https://github.com/rust-lang/book.
- [18] The Rust Unstable Book. 2022. url: https://doc.rust-lang.org/beta/unstable-book/language-features/generators.html.
- [19] Tokio: A runtime for writing reliable asynchronous applications with Rust. Provides I/O, networking, scheduling, timers, … 2022. url: https://github.com/tokio-rs/tokio.